Javascript parsing and compiling - Web performance with Steve Kinney (Frontend Masters)
Stats
- 100ms is the limit for having the user feel that the system is reacting instantaneously
- 1s is about the limit for the user’s flow of thought to stay uninterrupted, even if they will notice the delay
- 10s is about the limit for keeping the user’s attention
- 1s slowdown resulted 11% fewer page views, 7% less conversions - Aberdeen Group
- Akamai found that a 2s delay in web page load time increase bounce rates by 103%
- 53% of users will leave a mobile site if it takes more than 3s to load
- if you want users to feel like your site is faster than your competitors, you need to be 20% faster for them to notice
3 types of performance: Network, javascript (parsing & compilation), rendering
Based on the type of application your focus might be different.
For example a content website like the New York Times will focus on showing content as fast as possible, preferably with no loading bars and not care so much about how well the page performs in time or how much memory it consumes because the user will be switching pages often.
On the other hand a web app like GMail can take a hit on the initial load and make the user wait longer until fully loaded. But it needs to be performant in the long run and not have memory leaks because the user will probably keep that tab open the entire day and come back to it often.
An essential thing to do right at the start is to measure before making any change so that you are able to see if you’re being effective with the work you’re doing.
Another thing is deciding what’s worth optimizing and what’s not. A page that gets a lot of traffic and frustrates users in multiple ways is definitely at the top of the list. A page with low traffic like terms and conditions is not.
Javascript parsing and compilation
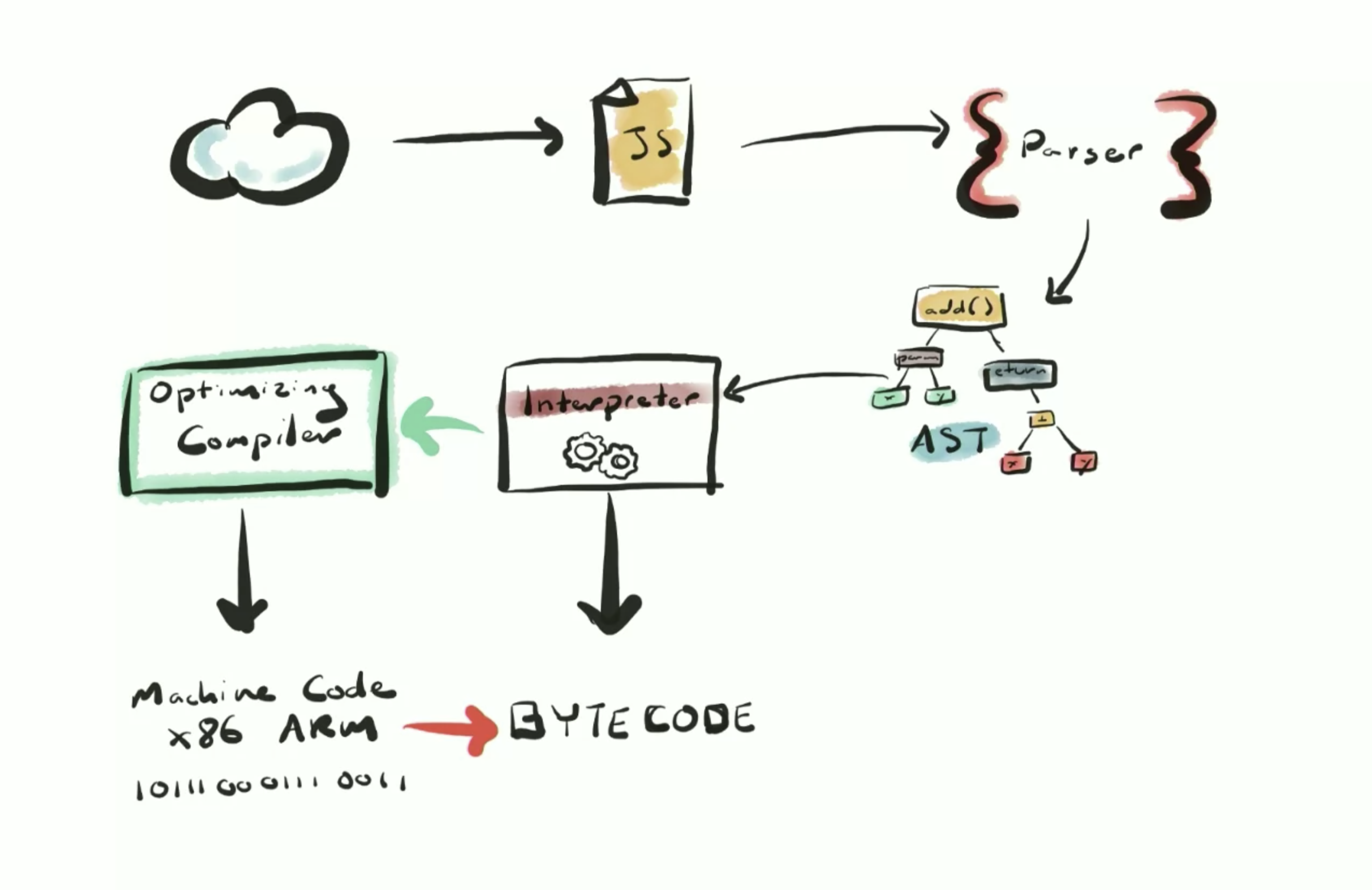
Parsing happens in 2 phases: eager parsing or full parsing which is what you’d imagine when you think of parsing and and lazy parsing or preparsing for things like functions declarations that are not to be used for the moment but which can be called on the future.
// These will be eagerly-parsed.
const a = 1;
const b = 2;
// This will be lazy-parsed meaning the body of the function will be parsed later when needed.
function add(a, b) {
return a + b;
}
// This will make the engine go back and parse the whole function.
add(a, b);
In the example above we’d take a cost hit on the lazy-parsing because we have to immediately do a full parse so the initial lazy-parsing was not worth it.
const a = 1;
const b = 2;
// The parentheses tell the engine to parse this now!
(function add(a, b) {
return a + b;
});
add(a, b);
However this would be a micro-optimization and most of the time you should just allow the engine decide what to eager or lazy parse. Or use a library like optimize-js that will do this for you in specific cases.
Once parsing is done we now have an AST (abstract syntax tree) which is a data structure that represents our code.
The AST goes into a baseline compiler (in the case of V8/Chrome it’s called Ignition) which is a just-in-time compiler (JIT) and what goes out is bytecode that gets executed by the runtime.
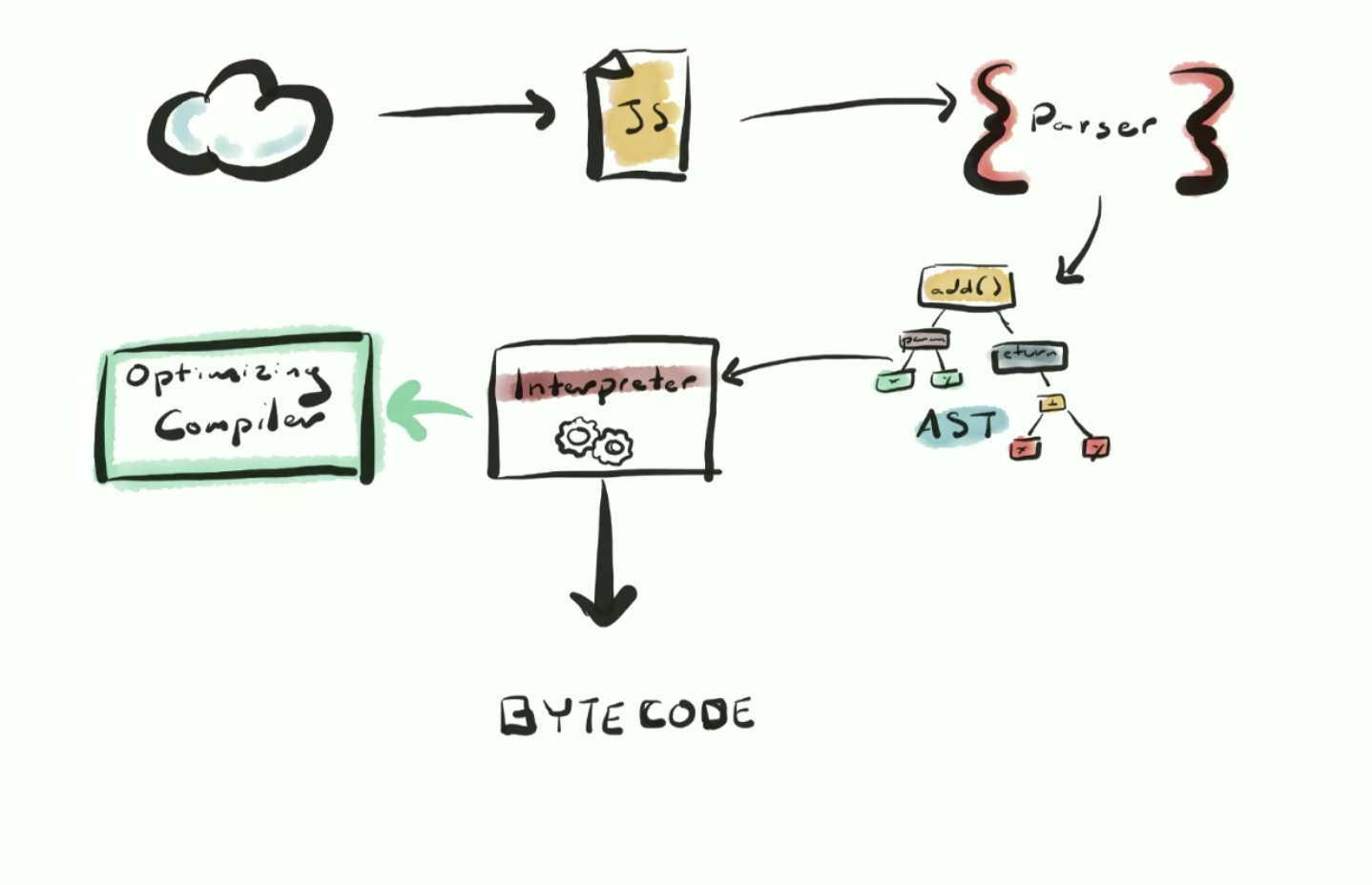
The JS engine includes a second type of compiler called an optimizing compiler (also a JIT compiler). In the case of V8 this is called Turbo Fan.
Because JS is a dynamic language and has a lot of rules, the interpreter (the baseline compiler) cannot make assumptions about your code. However once your code has run multiple times the engine can start making assumptions about the things that are needed vs rules that can be ignored and start optimizing your code.
For example when the interpreter goes over the ‘add’ function from above it cannot assume you’re going to add numbers, strings etc. It has to check all possible combinations of values for the arguments it might be given.
But once this function has been run a bunch of times it has become a hot function meaning the optimizing compiler will recompile it and based on the previous values the function has been called with, perform optimizations that will make your code run faster. This entire process is called speculative optimization.
We have 2 different compilers because they serve different purposes and work together to cover all needs. The baseline compiler is faster to start so it reduces startup latency because we can start running code immediately rather than wait on the slow optimizing compiler. It also allows the time necessary for something called inline caches to be gather type data on our code. This will help out the optimizing compiler speed up our code when its turn comes.
Inline caches
Even though JS uses dynamic types, the JS engine in browsers do use an internal type system. It will use this sytem to figure out if it can optimize our function calls.
Each operation like a property access, an arithmetic operation etc has an inline cache. When for example we try to access a property on an object, once the engine has done its work, it will also add an entry to that property access inline cache with the shape of the object it was called on. This is done because property access lookup is expensive so keeping a cache saves time.
Next time the same property will be looked up on an object, the engine will first look in the cache. If the new object it was looked up against has a shape that already exists in the cache, then we have a cache hit. If not, the new shape will be added to the cache.
The inline cache in V8 has up to 4 entries, if we look up the same property on objects with more than 4 different shapes, then V8 continues to cache them but it will add them to a global cache instead. The number of entries in an inline cache gives its name: monomorphic for a cache with a single entry, polymorphic for multiple entries up to 4 and megamorphic for values beyond 4.
For performance reasons we’d want either monomorphic (preferably) or at least polymorphic inline caches. If we have a megamorphic inline cache, it means that the engine has seen too many object shapes to keep tracking them in inline caches and it’s not good for performance.
This test shows what a huge difference in performance monomorphic vs polymorphic code makes.
The secret to understanding that code is to also keep in mind the concept of shape (hidden class of an object). In the code below, even though the objects look like they have the same shape for a human reading the code, they don’t as far as V8 in concerned:
function A() { this.x = 1 }
function B() { this.x = 1 }
var a = new A,
b = new B,
c = { x: 1 },
d = { x: 1, y: 1 }
delete d.y
This article, from where the above code snippet comes from, explains the concepts of inline caches and optimization in a lot of detail.
The 2 screenshots below show a V8 flag (the –allow-native-syntax) that you can use with Node to get access to an internal V8 function that allows you to compare the shape of various objects. There are more of these functions that you could use to test things.
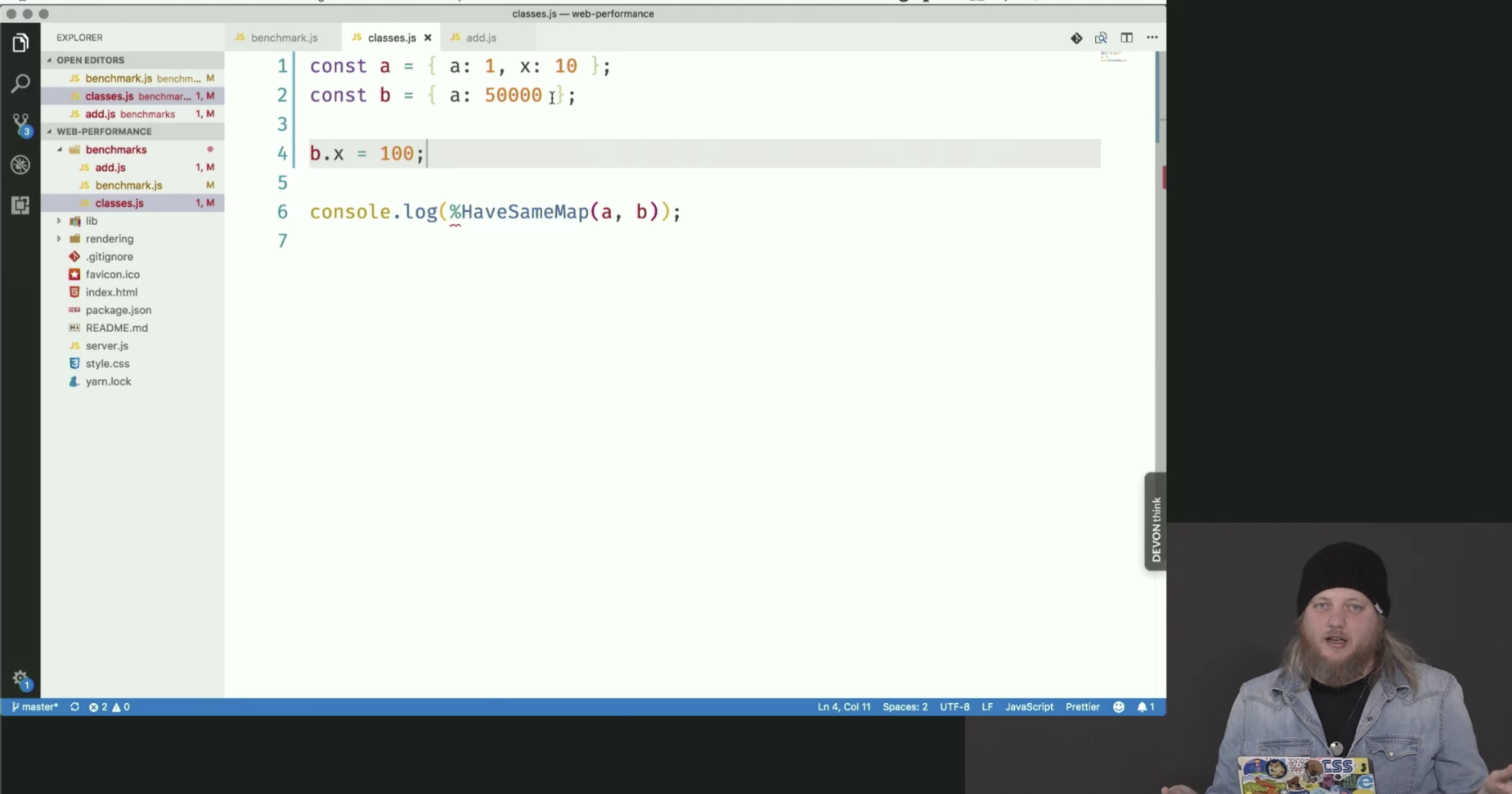
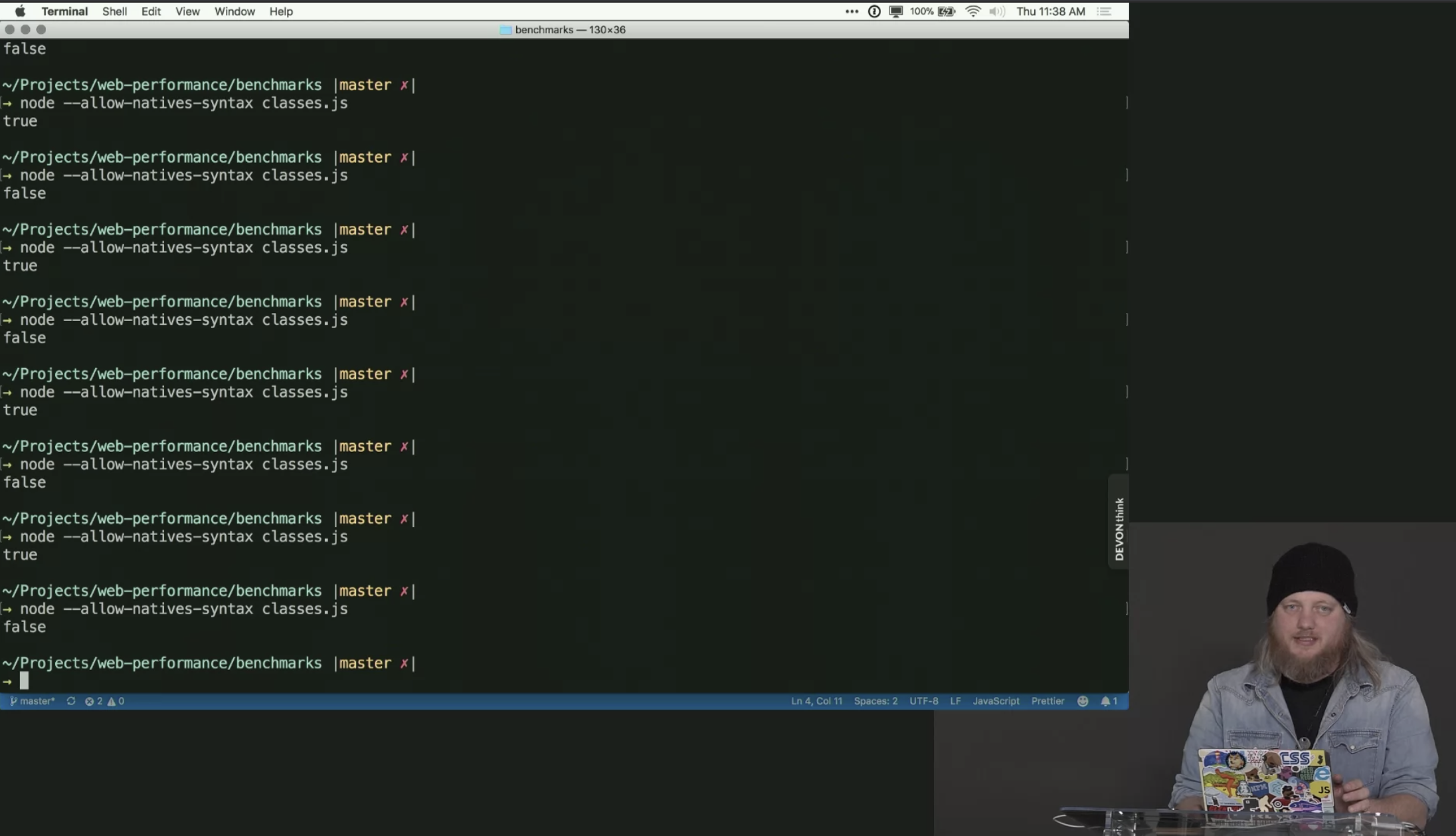
One other gotcha is related to scope and prototypes. In the snippet below, even though the point objects seem like they’re the same map, they’re not because the class is defined inside another function. Move the class declaration outside of the makeAPoint function and then the objects created inside will have the same hidden map.
const makeAPoint = () => {
class Point {
constructor() {
this.x = x;
this.y = y;
}
}
return new Point(1, 2);
}
const a = makeAPoint();
const b = makeAPoint();
console.log(%HaveSameMap(a, b)) // false
Function inlining
V8 will detect small functions which are being called many times over and it will go and replace the function call with the actual function body in all of those places. This makes your code faster because function calls are expensive due to adding a new frame to the call stack. Inlining the function body removes the need for that.
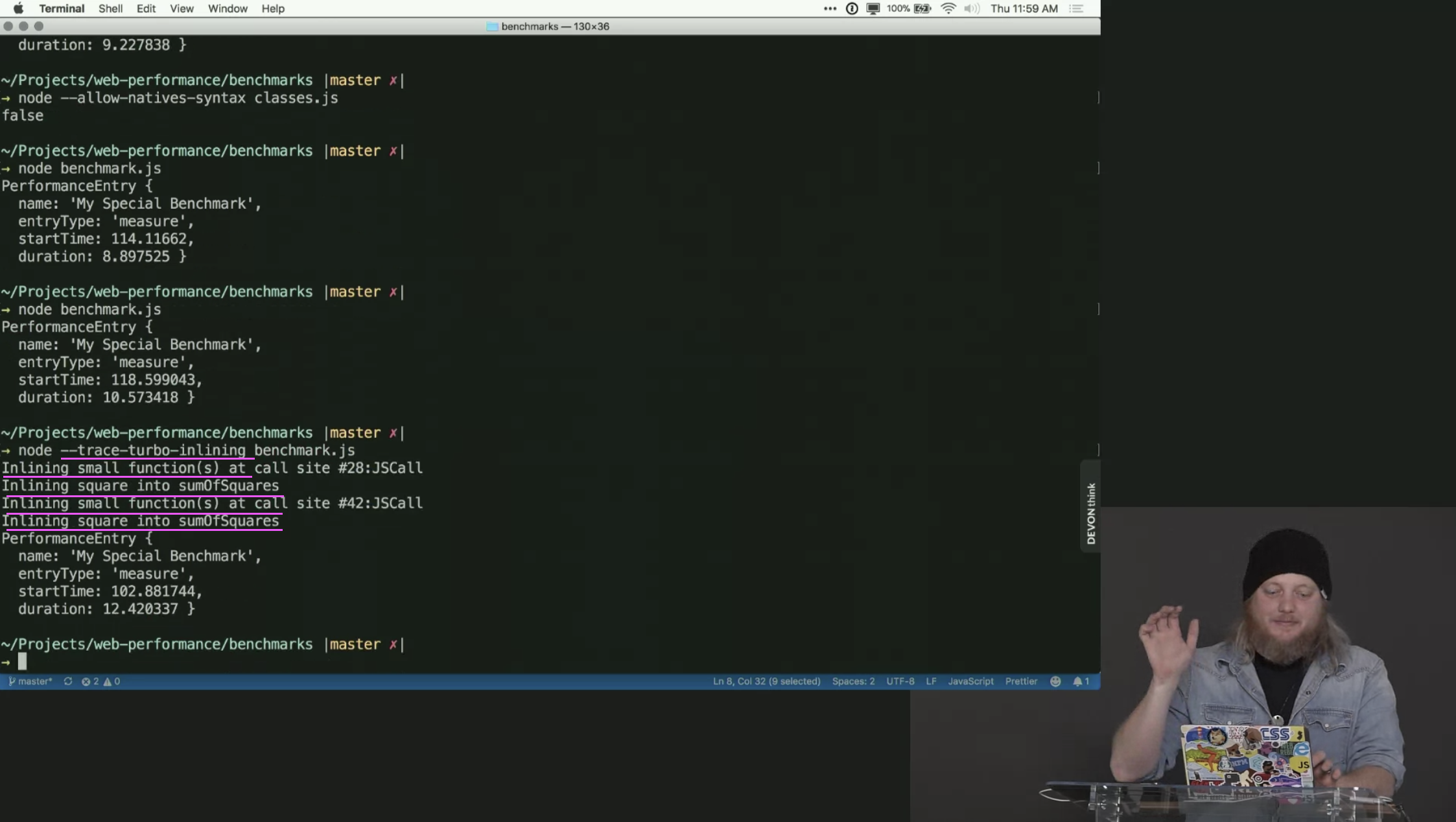
How can you use this knowledge to write better, faster code
So we now know that objects have a shape and that V8 runs faster on objects with the same shape. Therefore a good thing to do is to initialize all object members in constructor functions and not change their shape later on because that will cause V8 to change its hidden class and generate a new version of optimized assembly code that manipulates the differently shaped objects.
function Point(x, y) {
this.x = x;
this.y = y;
}
var p1 = new Point(11, 22);
var p2 = new Point(33, 44);
// At this point, p1 and p2 have a shared hidden class
p2.z = 55;
// warning! p1 and p2 now have different hidden classes!
When it comes to numbers V8 prefers when you use the same type of numbers and it particularly like 31-bit signed integers. This is a recurrent idea: try to write code as if JS had a static type system, be consistent with your values so that the engine can make as many assumptions as possible and have as little surprises as possible.
Arrays are very flexible to use in JS, we can put any type of value inside, we don’t care about the size etc. However they do have a hidden class internally and again, if the code is predictable it is faster.
- it’s more efficient to use array literals for small arrays because the engine can determine the hidden class right away rather then having to keep discarding hidden classes as it encounters new type of values being added to the array (hidden classes are immutable so they are replaced when things change)
var a = new Array();
a[0] = 77; // Allocates
a[1] = 88;
a[2] = 0.5; // Allocates, converts
a[3] = true; // Allocates, converts
// this is more efficient
var a = [77, 88, 0.5, true];
- arrays of doubles are faster; don’t store non-numeric values in numeric arrays
- it’s a good idea to preallocate small arrays before using them
These tips are compiled from this great article.
Measuring performance with the Performance API
You can use the Performance API, available in the browser to see how specific parts of your code perform.
let iterations = 1e7;
const a = 1;
const b = 2;
const add = (x, y) => x + y;
performance.mark('start');
while (iterations--) {
add(a, b);
}
performance.mark('end');
performance.measure('This is a custom name that you can give to your measurement', 'start', 'end');
const [ measure ] = performance.getEntries('This is a custom name that you can give to your measurement');
console.log(measure);
Deoptimizing
In the above example the add function will be marked for optimization which reduces the amount of time it takes to run considerably. This is happening because it’s a simple function and it’s being called with the same type of values consistently.
If we were to interleave some calls with different values like strings for example, it would be deoptimized and then reoptimized again when and if it starts behaving consistently again.